TL;DR
- Agile manages cadence, not inputs. Scrum and ADM provide iteration rhythm but do not address the structural variance in discovery, design, and developer handoffs that causes timeline slippage on Salesforce implementations
- Delivery leaders across the Salesforce partner ecosystem consistently report that most project risk enters before the first line of code. This is a discovery architecture problem
- Three phases drive the bulk of delivery variance: discovery scopes against incomplete org understanding, design pattern-matches without metadata constraints, and development handoffs invite reinterpretation. Current tooling addresses only the last phase
- Predictable delivery requires four structural elements: metadata-first discovery, constraint-aware design, specification-grade requirements, and continuous verification. Skipping any one and sprint cadence alone will not save you
- The partners who build AI-native delivery pipelines first will deliver faster, protect margins, and bid more aggressively on enterprise deals because their delivery risk is structurally lower, not because their project managers are more disciplined
Your sprint board is full. Standups run on time. Retrospectives produce action items. And your last three Salesforce implementations still blew past timeline and budget.
This is the reality at most Salesforce consulting partners. The methodology is sound. The certifications are current. The project managers are experienced. Yet predictable Salesforce delivery remains out of reach. By predictable delivery, this article means something specific: the ability to quote a timeline, hold a margin, and keep a client because every delivery phase produces verifiable, deterministic outputs grounded in org reality.
The reason is structural. There is a gap between Agile rituals and actual delivery execution that process discipline alone has never closed. This article is for the people who own that gap: Heads of Delivery, Practice Leaders, CTOs, and partner CEOs. It covers project delivery predictability, not revenue forecasting or pipeline management. And it argues that the fix is not another process layer but a fundamentally different delivery architecture.
The Predictability Illusion: Why Your Agile Delivery Org Still Misses Timelines
Adopting Agile and the Salesforce Application Development Model was the right move for most SI partners. Those moves were also not sufficient. Scrum and ADM provide a rhythm for iteration. What they leave entirely uncontrolled is what happens inside those phases: the unstructured, judgment-dependent work where most project risk actually lives.
Most SI partners have invested in Agile transformation: sprint boards, certified Scrum Masters, daily standups, and bi-weekly retrospectives. Some have layered Salesforce’s Application Development Model onto their delivery methodology, mapping Plan, Build, Test, and Deploy phases onto an iteration cadence. These were the right moves.
Agile delivery in Salesforce, as practiced by most partners today, manages cadence well but leaves the inputs to each sprint to chance. Consider a pattern that repeats across complex implementations. A Revenue Cloud Advanced engagement. Sprints 1 and 2 feel productive. The team hits velocity targets, burns down story points, and ships incremental work. Week 3 arrives. Someone discovers a custom CPQ integration touching 40 or more Apex classes that never surfaced during discovery. Velocity drops 20 to 30%. The sprint plan unravels. Rework begins.
This is not an outlier.
It recurs in complex implementations because the same cause is always at work: the discovery phase missed something critical, and the Agile process had no mechanism to catch it. Salesforce project timelines collapse not because teams are slow, but because the information those timelines were built on was incomplete.
Salesforce’s Application Development Model assumes continuous integration, automated testing, and frequent validation at every stage of development. In reality, most SI partners run a fraction of that testing intensity, with CI pipelines and code coverage treated as checkpoints rather than continuous verification mechanisms. The ADM framework was designed for Salesforce’s own product teams: organizations with deep institutional knowledge, mature automation pipelines, and continuous access to platform metadata. It was not built for consulting partners inheriting a new brownfield org every quarter. Adopting the framework’s rituals without replicating its underlying infrastructure creates an illusion of predictability. The process looks right. The outcomes remain unpredictable.
Where Variance Actually Lives: The Three Delivery Phases No One Has Automated
Timeline slippage is the symptom. The root cause is compounding variance that enters the delivery lifecycle long before the first line of Apex gets written. That variance concentrates in three phases, and current tooling addresses only one of them.
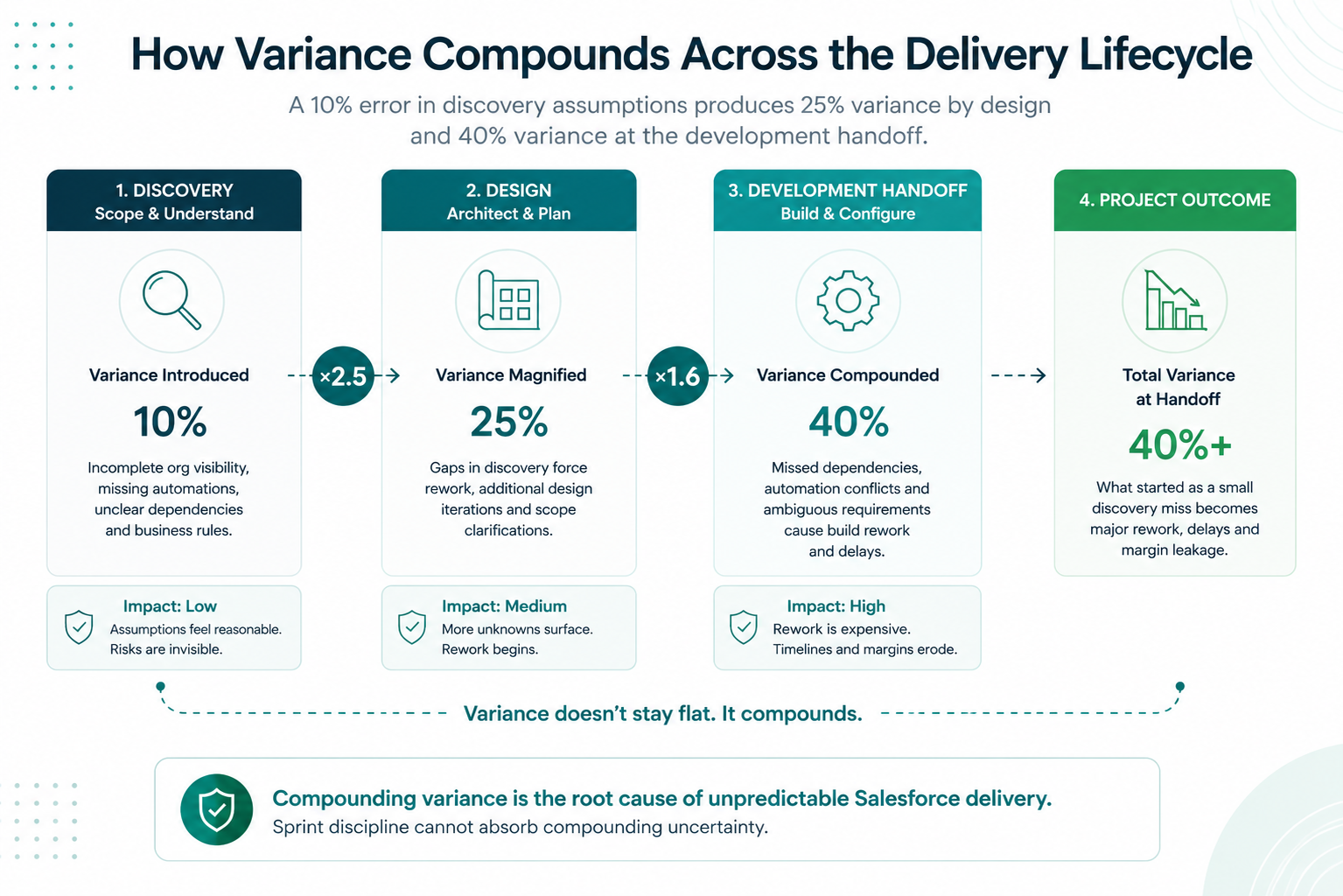
Discovery: Scoping against incomplete information
Most partners run discovery through stakeholder interviews and spreadsheet-based requirement gathering. This captures business intent reasonably well. It almost never captures the metadata-level reality of the existing org: custom objects, field dependencies, automation rules, validation logic, integration endpoints, and installed packages that will directly shape every downstream design decision.
Without a machine-readable picture of what actually exists in the org, you cannot accurately scope what needs to change. Every estimate becomes an informed guess, and informed guesses compound into timeline slippage across the entire engagement. A single missed automation conflict in a complex Salesforce org generates 80 to 120 hours of unplanned rework: the equivalent of three weeks of a senior developer’s time on work that was never scoped and cannot be billed.
Design: Pattern-matching without org constraints
Solution architects make design decisions based on experience. On greenfield implementations, that approach works reasonably well. On a brownfield enterprise org with 800 custom fields on Account and 47 Flows touching Opportunity, experience alone misses downstream impacts.
A field-level security change that breaks a Flow. A Process Builder that conflicts with a new trigger. A lookup relationship that should have been master-detail. These failures are predictable only when you are designing against actual org metadata rather than whiteboard assumptions. Architects who are skilled, experienced, and well-intentioned still miss these conflicts when the information they are designing against is incomplete.
Development Handoff: Prose specs, interpretation risk
The architect-to-developer handoff introduces interpretation gaps every time it occurs. Acceptance criteria live in Confluence pages as prose rather than as metadata-aware specifications. The developer reads the page, makes reasonable assumptions, and builds something that does not quite match the architect’s intent. The spec allowed multiple valid interpretations, and the developer chose a different one. That is not a people problem. It is a structural gap that has persisted because the tooling between the kickoff call and the first line of Apex has barely evolved over fifteen years.
Current tools address deployment variance effectively. But they start at code commit, which means they cover roughly 20% of the delivery lifecycle. The other 80%, where most project risk originates, runs on manual effort, institutional knowledge, and senior-heavy staffing. Process optimization efforts focused only on deployment are solving the wrong slice of the problem.
The Real Cost of Unpredictable Delivery for Salesforce Partners
Unpredictable delivery is not a single-project issue. It is a compounding P&L problem that affects every engagement your practice runs simultaneously. The costs appear in four places, but only one of them shows up on the sprint board.
Margin erosion
Every rework cycle, every unplanned discovery session, every “we need one more sprint” conversation eats directly into gross margin. The typical costs associated with Salesforce implementation range from $75K to $300K or more for mid-market and $500K or more for enterprise. A 15% rework rate on a $300K engagement means $45K in lost margin. Most partners absorb that cost silently rather than renegotiating the SOW. On fixed-bid engagements, every additional hour comes straight off the bottom line. The math is straightforward: total contract value multiplied by your rework percentage equals absorbed margin loss.
Talent bottleneck
Your best architects and senior developers are your most expensive resources. When delivery runs unpredictably, those people spend their weeks firefighting current engagements rather than starting new ones. A 50-person delivery org with 10 senior architects should be cycling onto fresh projects monthly. Four architects stuck in rework loops means effective delivery capacity has dropped 40%, and the pipeline stalls with it. More partners, more concurrent engagements, and the same manual delivery model mean the variance problem scales with every new SOW signed.
Client trust erosion
Enterprise clients buying Sales Cloud or Service Cloud implementations expect partner-grade reliability. One blown go-live, and the next phase goes to a different partner. The lifetime value loss dwarfs the margin hit on a single project, and the trust loss never shows up on a sprint board. In competitive markets where enterprise clients have increasingly sophisticated benchmarking data on implementation timelines, a single overrun creates a reference point that follows a partner into the next evaluation cycle.
Scaling impossibility
If every engagement requires senior-heavy staffing to manage uncertainty, the practice cannot grow without a proportional increase in headcount. Revenue scales with people, not with methodology. That is the ceiling AI-native delivery approaches are built to remove. The inability to decouple throughput from headcount is not a management failure. It is the natural consequence of a delivery model that has not fundamentally changed in fifteen years.
What Predictable Actually Requires: A First-Principles Delivery Model
Predictable Salesforce delivery requires a system where every phase produces deterministic, verifiable outputs. These are the four structural principles that make that possible. Skip anyone, and the sprint cadence alone will not save you.
Metadata-first discovery
Any delivery framework that does not start with a machine-readable audit of the client’s org is guessing. Automated org analysis should map objects, fields, automations, integrations, installed packages, and technical debt before the first stakeholder call. This makes conversations dramatically more productive because you walk in already knowing what the org contains, rather than hoping stakeholders remember to mention the critical Flow that fires on every Opportunity update. The principle behind AI-powered discovery and agentic development rests on this foundation: org understanding comes first and feeds every downstream decision.
Constraint-aware design
Solution design must be generated against actual org constraints. If the target org has hundreds of custom fields, dozens of Flows, and undocumented integrations that push data to an ERP, the implementation roadmap needs to account for all of it from day one. Design that ignores the existing org state leads to rework. Design that incorporates it produces a deployable architecture. The distinction sounds obvious until you consider how rarely the tooling between discovery and design actually enforces it.
Specification-grade requirements
The handoff between design and development must be machine-parseable, not a Confluence page with bullet points. Metadata-aware specs that reference actual objects, fields, and automation patterns give developers a precise build target and close the interpretation gap that causes rework. When a spec references a specific custom object, a specific field on Account, and the specific Flow that governs the trigger sequence, there are no valid alternative interpretations. The developer builds what the architect designed because the spec is precise enough to permit only one valid reading.
Continuous verification
Quality gates belong at every phase, not only at deployment. Automated validation should confirm that design decisions do not conflict with existing org state before anyone writes code. Finding a design flaw during UAT is the most expensive point in the delivery lifecycle to discover it. Finding it during design costs hours. Finding it during testing costs weeks. The cost-of-change curve in Salesforce delivery is not a gentle slope: it is a staircase, and each step up costs an order of magnitude more than the one before.
From Manual Scrum to Agentic Delivery: The Shift Already Underway
The Salesforce delivery industry is at an inflection point similar to when CI/CD tools transformed deployment a decade ago. The difference is that the transformation now hitting discovery and design is more consequential: it addresses the 80% of the delivery lifecycle that CI/CD tools never touched.
CI/CD changed how Salesforce code gets deployed. It did not change how requirements are gathered, how designs are produced, or how handoffs are structured. The upstream phases that generated the most variance, discovery and design, remained manual, judgment-dependent, and senior-heavy throughout the period when deployment became reliable. That is the gap that AI agents with native Salesforce metadata understanding now close.
What metadata-aware agents actually do
Specialized agents trained on Salesforce metadata can ingest an org’s full configuration, identifying complexity, existing automation logic, field dependencies, and integration footprints before a single stakeholder interview begins. This is not a generic LLM writing Apex from a prompt. It is a purpose-built system that understands the difference between a before-trigger and an after-trigger, why a master-detail relationship creates different sharing and rollup behavior than a lookup, and how a Flow that fires on Account update interacts with a trigger on Opportunity when the two objects share a relationship.
That level of org-specific understanding produces two outcomes that matter for delivery predictability. Discovery outputs are grounded in what actually exists in the org rather than what stakeholders described. Design recommendations account for constraints that would have been missed in a manual review. Both outcomes reduce the variance that compounds into timeline slippage.
Multi-agent architecture and parallel execution
Multi-agent architectures enable parallel execution of discovery across multiple workstreams: one agent analyzing the Sales Cloud configuration, another mapping Service Cloud entitlement logic, and a third documenting integration endpoints. Work that previously required sequential architect bandwidth becomes concurrent. Timelines that span weeks compress to days, not because the team is working faster, but because the work is being done simultaneously rather than serially.
For partners managing 3 to 5 concurrent client implementations, this change is significant. Senior architect time is the binding constraint on the number of engagements a practice can run at once. When AI agents handle the front-end discovery and design work that currently consumes that time, the architect’s capacity is freed for the judgment-intensive work that genuinely requires their expertise.
HighRev.ai as a concrete example
This is where the rationale behind HighRev.ai’s creation fits naturally into the conversation. HighRev.ai is a multi-agent AI platform built specifically to close the automation gap in pre-deployment phases of Salesforce delivery. When the Org Intelligence Agent connects to a client’s org, it reads the full metadata footprint: every custom object, field, Flow, Apex class, validation rule, installed package, and integration endpoint, producing structured documentation that the design agent then uses to generate solution architecture grounded in org reality. The development agent translates approved designs into deployment-ready code packages validated against the connected org before human review. Every phase produces verifiable, deterministic outputs rather than artifacts that depend on a specific person’s institutional knowledge to interpret.
The technology is not aspirational. It is operational. The question for practice leaders is not whether this architecture is real but how quickly they adopt it relative to competitors who are asking the same question.
What This Means for Salesforce Practice Leaders Right Now
Predictable Salesforce delivery is not a process goal. It is a competitive advantage that determines which partners scale and which ones stay stuck trading hours for revenue. Three time horizons frame the action plan.
Now: Audit your delivery variance by phase
Pull three to five recent engagements and map actual hours against estimated hours by phase: discovery, design, development, QA, and deployment. If timeline slippage is consistently originating in discovery or early design, that is a structural problem that no amount of sprint discipline will fix. Most practices track project-level margin but not phase-level contribution to overruns. Without phase-level data, you cannot identify which phase is driving the gap. For additional context on how those overruns translate into P&L impact, Salesforce project planning and cost management data gives you the baseline numbers to anchor the conversation with leadership.
Ask your delivery team one question: at what point in the project lifecycle does the team typically discover that the discovery phase missed something significant? If the honest answer is "mid-development," you now know the phase when structural investment has the highest leverage.
Next: Evaluate whether your toolchain addresses pre-deployment phases
If your automation starts at code commit, you have automated the last 20% of the delivery lifecycle. Evaluate whether your delivery toolchain addresses discovery, org analysis, design automation, and metadata-aware development, or only CI/CD. The evaluation question is not whether the tool does AI. It is whether the AI understands Salesforce metadata natively: the difference between a before-trigger and an after-trigger, why a sharing rule configured one way creates visibility problems when a new object relationship is added, and how permission set groups interact with record types across clouds.
Platforms like HighRev.ai allow partners to evaluate what AI-native delivery actually looks like in practice, against your actual org complexity, without ripping out existing processes.
Schedule a HighRev.ai demo to see how agentic delivery works against a real brownfield org.
Future: the partners who move first compound the advantage
The partners who build AI-native delivery pipelines first will win on two fronts. They will deliver faster at structurally lower cost, which means they can bid more aggressively on enterprise deals while maintaining margins their competitors cannot match. And they will accumulate org-audit patterns, effort benchmarks, and design templates, making every subsequent engagement faster. A competitor who adopts the same tooling six months later purchases the platform. They do not get the institutional learning built on top of it.
The margin conversation, the talent conversation, and the scalability conversation all converge on the same structural point: a delivery model built on manual discovery, human-dependent design, and prose-based handoffs has a ceiling. Sprint discipline raises that ceiling marginally. AI-native delivery removes it.